Getting started with web scraping for data analysis.

“You can't be a data scientist without making a data set” ~ kaggle
If you are scraping the data for data analysis or machine learning you are creating a dataset of your own ! Congratulations 🎉 . If you love this world of Data science and analysis you’ll come across a moment where you’ll need to create a dataset of your own and web scraping is your Brahmāstra for obtaining textual data. All the websites would keep updating so the web structure might change resulting that the code might not work but the effectiveness of the strategies will still remain intact.
I’ll sum it up for you
Yep not gonna bore ya all with copy pasting from the web but a quick intro to web scraping and what we’ll cover in this article. Web scraping is a method where you can extract n save data from the actual web pages 🤭 . There are already many sources so how is this article different ? , You’d ask. You’ll not only learn the basics of extraction of data but some abstractions which would make you adore the beauty of data extraction, Moreover we’ll cover how to complete incomplete data with automation and web crawling. Our project was to extract the college placement data of region Mumbai and Pune, Here’s the research paper link i’ll recommend you to just go through if u gonna implement this.
https://www.irjet.net/archives/V8/i6/IRJET-V8I6216.pdf
The Baby Steps
is there anything more beautiful than python 🥺, packages helping us are requests, beautifulSoup and pandas
requests : Will obtain the content of the webpages in form of code for us
beautifulSoup : Will help us extract the data by traversing and fetching the textual data from the html element it can be a <p> with some text
Pandas : It’ll provide us with dataframe it’ll hold our data for us

Note the code in above snippet won’t work as the website is updated for trying out the code you can consider the next example yet the strategy for extracting can still be used
Okay so we are directly jumping into the tricky part 😬 but we got this. now that you have already seen the code snippet, Many of you would have recognize this structure but I’ll still explain it in detail. After initializing the imports we fetch the content of website with help of requests.get and then we parse the content with BeautifulSoup after this you should view your source if you are using a notebook just run the code cell with src as our source is stored in it.
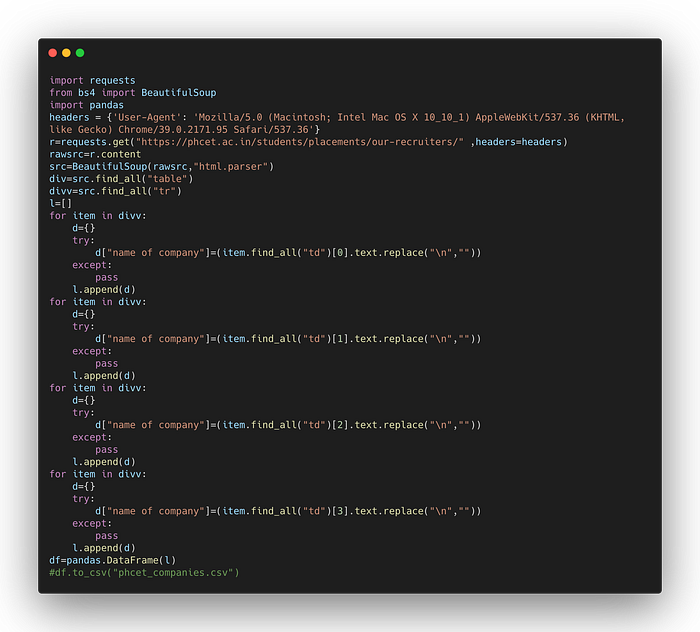
Remember the word abstraction ? 🤔 here if you can see the web page that we are extracting it doesn’t contains text but images. But we already have our source which knows everything 😌 it’s huge though Verbos ! Pro Tip ✨ just do a quick search by cmd + F and search of what you want to extract for me it was a name of company and I could see many names, I just searched one of it and found the structure the values were in “alt” descriptor of img tag in html. Now that we want all the name of companies to be extracted we use find_all since the information in <img> tag we have specified it as img with the class name assigned to it as all the companies had same class name. and then we appended it into dataframe and exported the csv files. So even though there are many ways the data can be present in various structure you still can extract it.
Similar to above example you’ll find many variations on my github repo which contains variations of extracting the information from table, div, and even in html fragments which appear dynamically.
Tricking the websites : Not a bot 🤖
headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36'}url = 'enter_your_url'r= requests.get(base_url+str(page)+'.htm',headers=headers)
Pasting the url of the website, That easy Right? Yeah but There’s a catch though a website may consider the program as a bot and would deny sending the page source.This is very easy step to trick the web source that may deny your access to fetch the page source for, you guessed it right they don’t want you to scrape the data. Header considers the meta information of your computer which can spoofed this will allow you to scrape your data. Further enhancing this you can even create a virtual device and assign it a virtual mac address as well. In our scenario we got through just by simple header trick.
Another one : Tabular example 💁
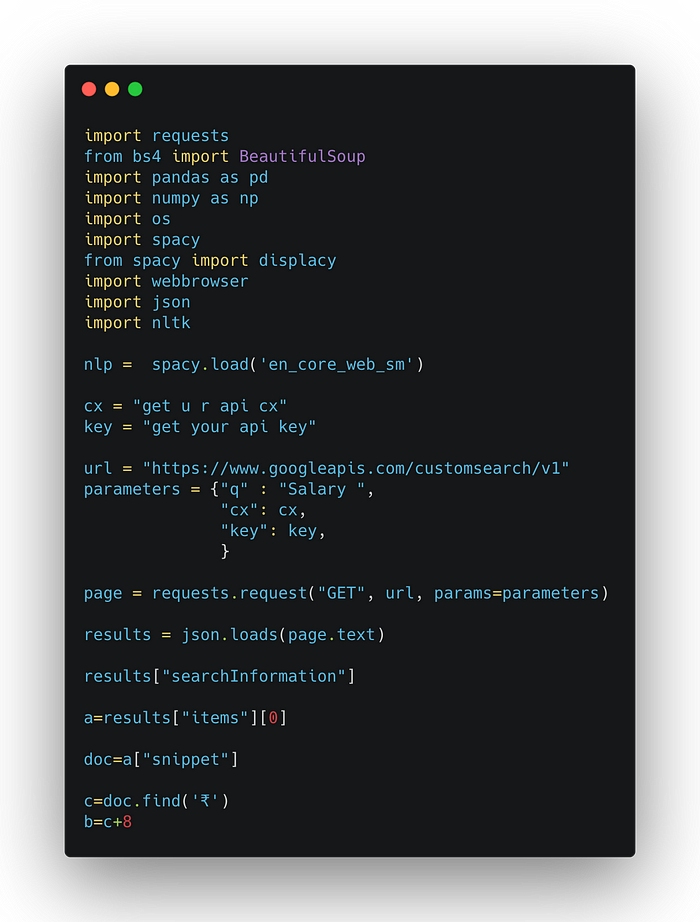
Similar to the above extraction method we added headers to avoid the forbidden access and the strategy used for extraction here is known as component digging. Dig down the nested html elements until you find the data for extraction which can be looped. Simplifying steps further the html elements were just drill down consider it as a Mine !
Layer1 | Layer2 | Layer3 | AmethystSimilarly
Src | Table | Tr | Td | DataYou all can try and experiment this code on your own it’s updated to work all the code snippets below are working as well 🧑🏻💻.
Automate it : The checkmate ♛
Here is another part which is mocktail of Natural Language processing and web scraping. As you have seen that we have scraped the college name from our web source but now we need the salaries which corresponds the company at the present year and in present region.
Here is an brief idea of the automation snippet now you can use the Google api to generate custom query. we would need our query to be somewhat like this “salary for company company_name in region_name for year year_number” since we have extracted all the values the bold column names inside the query before. we can load Dataframes from csv and for each row in we can place the values inside the search query, Additionally you could include fresher role in query. We want the missing amount value additionally we know that it starts with ₹ for INR so just find the currency symbol and then extract the numeric entries ahead we just used 7 digits ahead cause we already studied the query results, Worked like a charm ✨.
Crawling is the way : web crawling 🕸
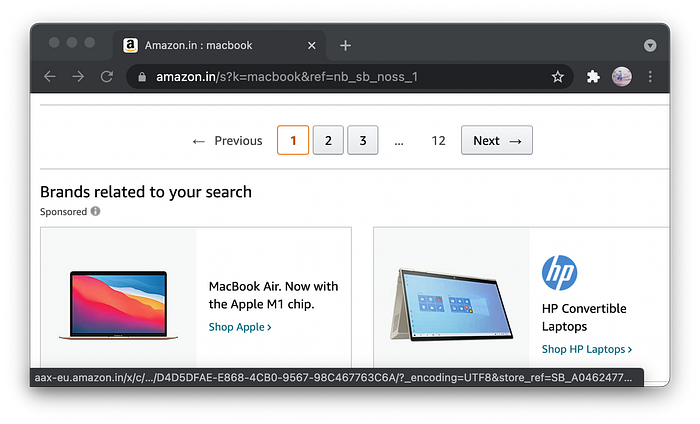
Web Crawling simplified ! Some web pages contains pagination, pagination is something like you see on amazon.com where u search for a product and there are various results but also various pages. If you have noticed the structure of these pages are same, right. Additionally if you have noticed the link remains same as well but just a single digit changes !
https://www.amazon.in/s?k=macbook&page=2&qid=1624594558&ref=sr_pg_2https://www.amazon.in/s?k=macbook&page=3&qid=1624594582&ref=sr_pg_3
If you refer to above link you can see that the page number are the only thing which are updated. Now why is this a huge deal for us, We could extract the pages one by one ? Nope we use this crawling technique to scrape the similar information.
Let’s crawl : Putting it together 😶🌫️
We have everything crucial for implementing a web crawler. Lets crawl glassdoor for reference and extract the salaries and companies for matching the missing values of our previously obtained dataset of college which only contained images.
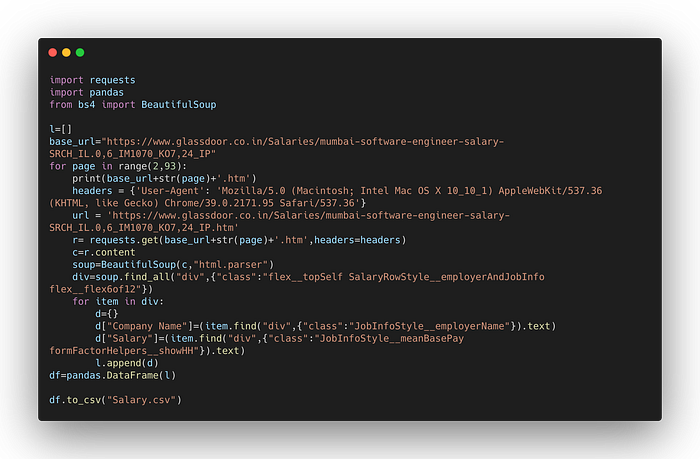
In order to scrape all the data from number of pages we need to know the end limit of the page which can be easily known just by looking at the pagination count. We are going to use the knowledge that we have already learned and as the page number changes in the url we will use string manipulation techniques to generate our urls, As you can see our loop is going to run for 92 times and at each iteration it will insert the number in url as you can see below.
r= requests.get(base_url+str(page)+'.htm',headers=headers)After getting the url we will scrape the necessary data which is similar to the process that we already discussed. I’ll still snippet it down below so you can grasp on the block that I’m mentioning here.
c=r.content
soup=BeautifulSoup(c,"html.parser")
div=soup.find_all("div",{"class":"flex__topSelf SalaryRowStyle__employerAndJobInfo flex__flex6of12"})
for item in div:
d={}
d["Company Name"]=(item.find("div",{"class":"JobInfoStyle__employerName"}).text)
d["Salary"]=(item.find("div",{"class":"JobInfoStyle__meanBasePay formFactorHelpers__showHH"}).text)
l.append(d)
df=pandas.DataFrame(l)Moving forward you can simply append it to your dataframe and export it as csv or xlxs as your preference. This gives you freedom for column matching to get those incomplete values filled effectively upto 80% accurate.
Wrapping things up : Conclusion 🥳
It’s just so easy to love the field of data science and analytics it makes you research on various interesting topics and excavating the outcomes which are dug and yet to be found. Me along with my team members and project guide were successful generating the dataset as well. I’ll link the dataset below if you liked the dataset please considering upvoting the dataset and sharing this article. I’d like to thank and mention our project guide Sharvari Govilkar for guiding us and motivating us to select a topic which was not researched, regionally exclusive and most importantly would contribute and help the placement team. I’d thank our team members Akhilesh Shinde, Aniket Shinde, and Vivek Singh for contribution towards work. It was indeed a memorable experience. I’ll create an article on publishing a dataset soon, Till then happy coding everyone 🦦.

